1. Set of documents
This document is one of the specifications produced by the ResearcherPod and ErfgoedPod project:
-
Artefact Lifecycle Event Log (this document)
2. Introduction
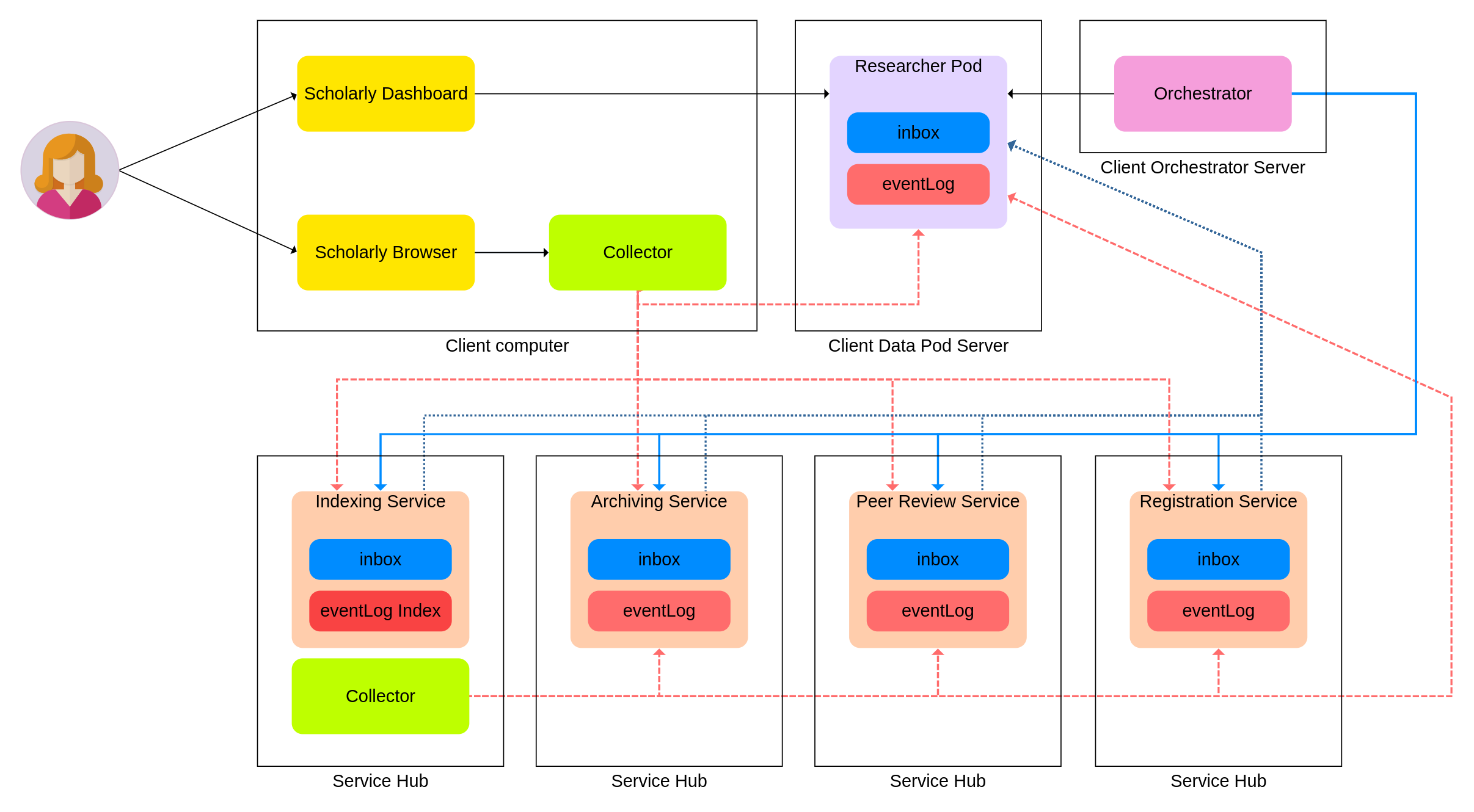 The Collector is an Autonomous Agent that traverses the scholarly network to gather event information on specific artefacts.
It has the task of gathering all useful information it can, and ranking it according to the preferences set by the actor running the collector instance.
The main usecase of this component will be in addition to existing third party indexes for scholarly artefacts such as Google Scholar and Arxiv.
The component collects information from the Web by crawling the network, taking into account the actor’s preferences of trusted sources.
The Collector’s discovery process requires the materialization of three capabilities: selection, ranking, and verification of retrieved artifact event information.
The Collector is an Autonomous Agent that traverses the scholarly network to gather event information on specific artefacts.
It has the task of gathering all useful information it can, and ranking it according to the preferences set by the actor running the collector instance.
The main usecase of this component will be in addition to existing third party indexes for scholarly artefacts such as Google Scholar and Arxiv.
The component collects information from the Web by crawling the network, taking into account the actor’s preferences of trusted sources.
The Collector’s discovery process requires the materialization of three capabilities: selection, ranking, and verification of retrieved artifact event information.
3. Definitions
This document uses the following defined terms from Overview of the ResearcherPod specifications § definitions:
-
Autonomous Agent
-
Artefact
-
Lifecycle Event
4. Collector interface
A Collector component MUST be deployable as a local background process or as a remote web service. A Collector component MUST provide an interface on initialization through which the initializing actor can set the starting parameters for the component. This interface MUST include the possibility to set one or more target artefact URI’s, for which the component must crawl the network to discover Event information. Additionally, the interface MUST support setting an initial set of data sources the component may crawl, mapped to a set of trust scores for each data source indicating the actor’s trust in a certain data source. On intialization, the collector automatically starts the collection process. This provisioning MUST be possible using a PUT or POST to a dedicated [HTTP1.1] resource if the orchestrator is deployed as a remote web service.5. The Collection Process
The Collector component gathers Artefact event information in the decentralized scholarly communication network. It’s main target is the collection of bot Lifecycle Event and Interaction Event information on the target artefacts in the network. Based on the parameters passed on initialization, the component crawls the network for this information. The component can be initialized with no target artefacts, in which case it SHOULD crawl the network, and return all information for all discovered artefacts to the initializing actor.5.1. Selecting
The first step in the selection process is selecting the data sources which the collector instance will crawl. Initially, the available sources include the URI of the artefact for which information is sought, as well as the set of available data sources and their trust score assigned by the actor. During the crawling process, the collector will come accross new links that may lead to new data sources. These data sources MUST be added to the sources index with a trust score based on the user preferences or derived from the data source it was discovered in. The actor initializing the Collector component SHOULD be able to set the logic for the assigning of these trust scores on initialization. The algorithm deciding in which order the data sources are crawled MUST be based on both the trust score of the data sources and the type of data expected to be found in the data source. Any subsequent of concurrent collection tasks with other target URIs SHOULD make use of the updated sources list created through other collection tasks to speed up discovery. An example algorithm for the selection process is given in § 6.1 The selection algorithm.5.2. Ranking
On crawling the data sources, Event information may be discovered on the target artefact. These discovered Events MUST display and may be ordered according to their resulting trust factor, in combination with the other defined filters by the actor. The trust factor given to an Event MUST initially be deduced from the trust factor of the data source on which it was discovered. An example ranking algorithm is given in § 6.2 The ranking algorithm. On verification of the Event in the verification step, this trust score MAY be adapted based on the trust in the service that created the event and with which it was verified.5.3. Verifying
After the retrieval of an Event, the collector MAY choose to try to verify the authenticity of the discovered event information. This functionality MUST be available either automatically or through an interface where the actor can specify specific Events to verify for the collector. Event information can be validated according to the algorithm described in § 6.3 The validation algorithm. Data corruption of any kind should be warned to the user. We define corruption as any truncation or alteration to an artifact or its metadata. In the case of versioned data, the verification step MUST take into account the vesions of the resources, and verify for the specific versions of the resources that are defined in the dat.6. The proposed algorithms
6.1. The selection algorithm
The Collector selection algorithm has the task of discovering and crawling the available data sources for artefact Event information on the network. The algorithm MUST6.1.1. Implementation
-
Dereference the artefact, discovering any defined Event Log instances according to the Event Log spec.
-
List all found Event instances.
-
Discover the data sources of all event instances, and add all data sources to the list of data sources. The trust factor of these sources MAY be adapter from the trust factor of the current data source.
-
Repeat untill a cutoff treshold value is reached: a. Pick highest trust score data source from priorityqueue (score may be adapted using additional filters) b. Dereference the data source and add the event information to the listing c. Add all discovered data sources to the priorityqueue.
The discovery of data sources in an Event Log happens by taking the origin of all listed Events.
6.2. The ranking algorithm
The Collector ranking algorithm has the task of ranking the discovered Events connected to the queried artefact. This ranking is adaptable, as entity ranking may change on verification of the discovered event or on adaptation of the data sources trust scores used by the algorithm. The used algorithm (parameters) must be adaptable through the collector interface.6.3. The validation algorithm
The used validation method will depend on the available data.6.3.1. Implementation
-
Discover the origin of an Event
-
If the Event has a digital signature, verify the signature with the origin
-
If the signature verifies, confirm the verification of the event.
-
If the signature does not verify, flag Event as tampered with.
-
If the origin is not available, mark as unresolved. These events can be verified by discovering matching events in archived versions
-
-
Index the Event. If any identical event is come accross, mark as validated.
Any Event MUST have a defined origin. To validate an Event, the first step MUST be to dereference the Event origin. The validation algorithm MUST include
Multiple methods of verification can be used:
-
A first approach to verification of events is redundancy. By cross-referencing any found events with the events stored by the actor generating the event, the collector can assume that if a matching event can be discovered, the event can be presumed as not falisified.
-
A second approach makes use of trusty URIs. Any event generated by another actor in the network can add the link to the original event using a trusty URI. On discovery of the event, the collector can check the origin of the event, and flag adaptations in the original. - this is not super useful, as this only protects against services altering the information in an event, and in case of a non-match you cannot really prove you have the original?
-
Finally, digital signatures can be added to stored events. Digital signatures are currently in development in a W3C working group. Through digital signatures, the collector can verify the origin of an event by matching the signature for the event with the public key of the service that generated the event. This way the collector can verify the origin and contents of the event. (This does not require a lookup in the service event index to find a matching event).
Note: These mechanisms provide solutions for verifying the origin and contents of an event found in an event log. In case of an event not mentioned in the event log of an actor, the collec:+1: tor has no way of discovering this.
7. Deploying a collector
A Collector MUST be deployable as a local background process or as a remote web service. In case of the latter, an actor SHOULD be able to spawn, initialize and trigger the instance over [!HTTP1.1].POST /test HTTP/1.1
Host: collector.service
Content-Type: application/json
Accept: application/json
{
target: "http://target.artefact.uri",
datasources: {
"http://data.source/1": 1,
"http://data.source/2": .8,
"http://data.source/3": .5,
"http://data.source/4": 0,
},
filters: [
...
]
}
If deployed as a local background process, an (custom) API MUST be present that is able perform these actions.
8. Updating collector targets
9. Notes
9.1. Deleted Events
10. Spec roadmap
-
Consolidate discovery and verification algorithms
-
Specify interfaces for component
-
creation interface
-
running interface
-
retieve current results + ranking
-
update targets ? - new process?
-
-
-
Create flow graphs for the different use cases.
-
Specify implementation details.
Appendix A: Implementation details
Retrieving inbox notifications
Observing LDP resource state updates
Time based trigger implementations
11. Acknowledgement
We thank Herbert Van de Sompel, DANS + Ghent University, hvdsomp@gmail.com for the valuable input during this project.